欢乐炸三张金花游戏app中国官方最新版 让矩阵归模拟, 让逻辑归数字! 这家中国团队重新界说了蓄意机

黄仁勋的GPU,解一谈矩阵方程,要作念上亿次乘法。
一家中国公司,一步就给解了,用的是模拟蓄意。
这家公司叫安纳智芯(Anatrix)。

往时几年,整个这个词AI行业险些都在往消释个标的决骤。GPU、TPU、LPU、CPU……民众卷来卷去,本色上卷的其实照旧数字蓄意:
更多晶体管、更先进的制程、更大带宽、更高蒙眬。
但最近,咱们发现存一批公司,驱动不按这个逻辑走了。
安纳即是其中之一。
他们采选的,是一个依然千里寂已久、但这两年又驱动火热的标的:
模拟蓄意。
这个宗旨听着新,其实少量都不新。
早在数字蓄意机大范畴擢升之前,东谈主类就依然在谈判模拟蓄意。最近很火的存算一体、光蓄意、量子蓄意、类脑芯片,往大了说,本色上也都属于这条路子。
之是以这两年重新被和蔼,一个很迫切的原因在于:
模拟蓄意自然具备更高并行度、更低功耗,何况不像数字芯片那样高度依赖先进制程。
但它的问题也很彰着,数字蓄意本色上处理的是0和1,只消能分裂高下电平,纰缪就能被不停改变。
而传统模拟蓄意由于是径直用物理信号暗示信息。电压、电流、电导这些量在传播进程中,容易积贮噪声和漂移。
矩阵范畴越大,纰缪放大得越夸张。
往时几十年,数字蓄意靠着摩尔定律沿途狂飙,精度被不停“硬堆”上去;而模拟蓄意诚然表面上更高效,却永久困在精度问题里。
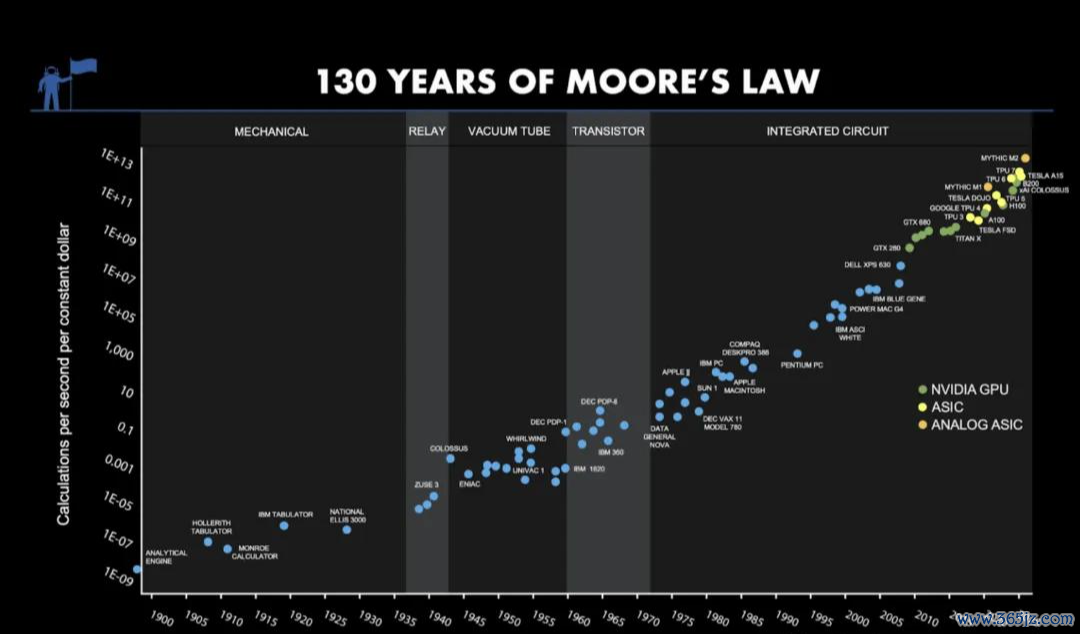
行业里以致一直有一个很流行的不雅点:模拟蓄意很快、很省电,但不简直。精度,也因此成了模拟蓄意近几十年来最大的死结。
而安纳作念的,即是把它解开。
模拟蓄意的精度,不再是问题了
往时近十年里,安纳的中枢科学家一直在作念消释件事——
把模拟蓄意的末端,作念得充足简直。
客岁,团队完成了精度比好意思数字芯片水平的旨趣性考证,在模拟蓄意边界达到断档式早先,而本年,有关芯片现时依然投入流片阶段。
在时期路子上,安纳走的是一条越过典型、但也越过“硬核”的模拟蓄意路子:
基于存储器阵列,搭建非冯诺依曼架构芯片。
节略来说,即是把矩阵方程径直映射进物理电路,让电路本人成为方程求解器。
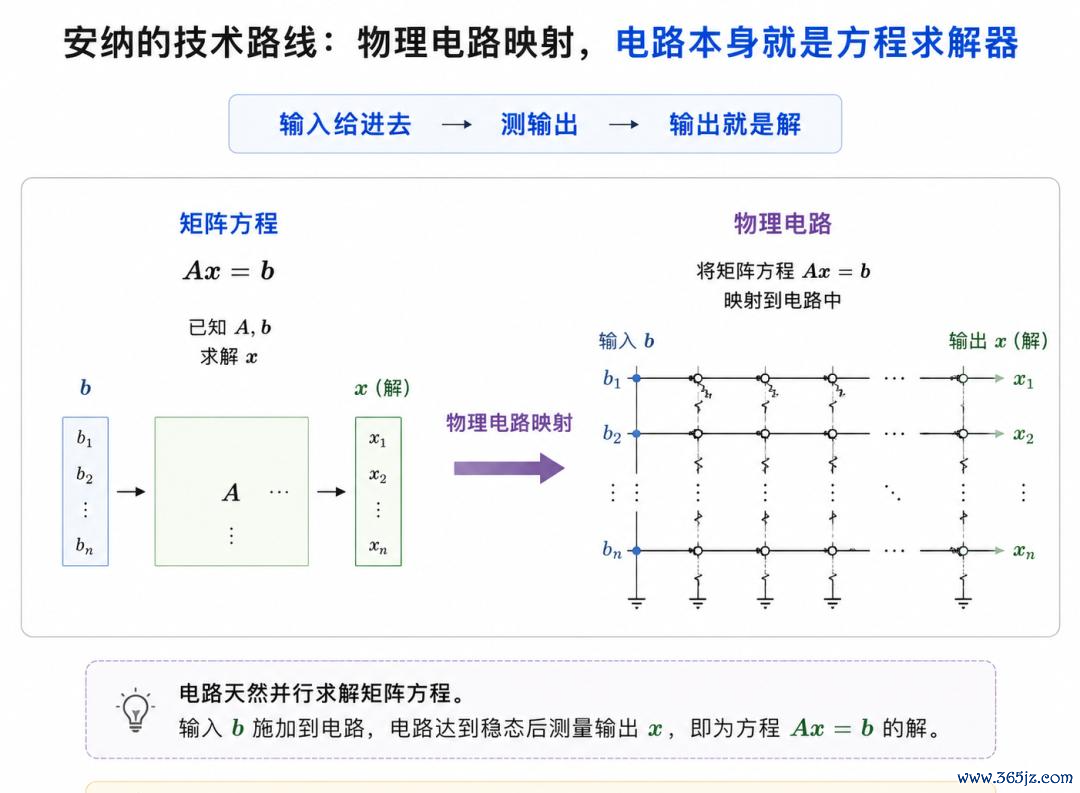
输入给进去,测输出,输出即是解。
也正因如斯,那些GPU没主见径直求解、只可靠海量迭代迫临的矩阵方程,在安纳这里,不错一步完成,并保执精准。
博亚体育2026世界杯中国官方入口(注:GPU拿到一个512×512的矩阵方程后,第一件事并不是“径直解”。它会先把问题斥逐、转置、理会,再转动成海量矩阵乘加运算,通过一轮轮迭代逐步迫临谜底。整个这个词进程,时常需要上亿次乘法。)
但非凡念念的是。
即便精度问题驱动被措置,今天大大都模拟蓄意公司依然莫得遴荐这条路。
像Unconventional AI、Normal Computing、EnCharge AI这些近两年最受和蔼的模拟蓄意创业公司,主打的依然是低功耗、存算一体或者特定场景加快。

(注:模拟蓄意正在重新取得老本市集和蔼。2025年底,主打低功耗模拟芯片的 Unconventional AI在种子轮便取得Lightspeed Venture Partners和a16z攀附领投的4.75亿好意思元融资,估值接近45亿好意思元;专注热力学蓄意的Normal Computing于本年3月完成由三星领投的5000万好意思元融资;而存算一体公司EnCharge AI客岁也完成了越过1亿好意思元的B轮融资。)
这背后其实对应着两种都备不同的谈判形而上学。
一种念念路是给与模拟蓄意存在纰缪,在低精度条目下寻找“够用”的利用场景。
另一种念念路,则是先把精度作念到极限,再商讨成果和成本。
安纳属于后者。
在与量子位疏导时,团队反复提到一个不雅点:
整个蓄意平台的发展历史,险些都是先把精度作念到天花板,再左证场景需求向下作念选择。
数字蓄意亦然如斯,AI模子考验里,先有FP32,再向下兼容FP16、INT8、INT4。
要是一驱动就在低精度里寻找“够用”,许多才智可能永远莫得契机被考证。
从上世纪80年代末的类脑蓄意,到自后的模拟神经收罗,再到今天的存算一体,雷同的故事其实依然反复出现过许屡次。
是以,并不是追求精度这件事有争议,而是在往时很耐久间里,由于模拟蓄意精度低是固有的,民众停留在这一层面,存在领会上的偏差,于是只可退而求其次。
而安纳率先完成了领会上的打破,他们信得过想作念的,即是把高精度模拟蓄意推向可用。
整个东谈主都在作念乘法,欢乐炸三张金花游戏app中国官方最新版安纳想把“除法”补追溯
除了对精度的格调,安纳和其他模拟蓄意公司的不同,还在于他们选了一个都备不相同的标的:
矩阵求逆。
今天作念模拟蓄意的公司,不论是存算一体、模拟CIM,照旧多样类脑、光蓄意路子,险些都在作念矩阵乘法。
这其实很好意会,因为整个这个词AI产业,本色上即是建造在矩阵乘法之上的。
一方面,GPU本人就极其擅长矩阵乘法;另一方面。大模子推理,也险些全是矩阵乘法,是以
整个这个词行业的念念路都很当然——
既然模拟蓄意更省电、更并行,那就拿它去替代一部分GPU的矩阵乘法,但安纳并莫得这样作念,他们遴荐了更第一性的矩阵求逆。
那么,矩阵乘法和矩阵求逆有啥不相同呢?
节略来说,矩阵乘法,本色上是“知因求果”。权重已知、参数已知,乘起来、加起来,临了得到末端。
而矩阵求逆反过来。末端依然知谈了,但中间信得过的参数、权重、景象未知,你需要反过来把它求出来,从末端反推原因。
对应到大模子里也很好意会:矩阵乘法更多对应推理,而矩阵求逆则更接近考验。
因为考验本色上,即是已知输入和输出,再反过来寻找中间最稳健的参数。
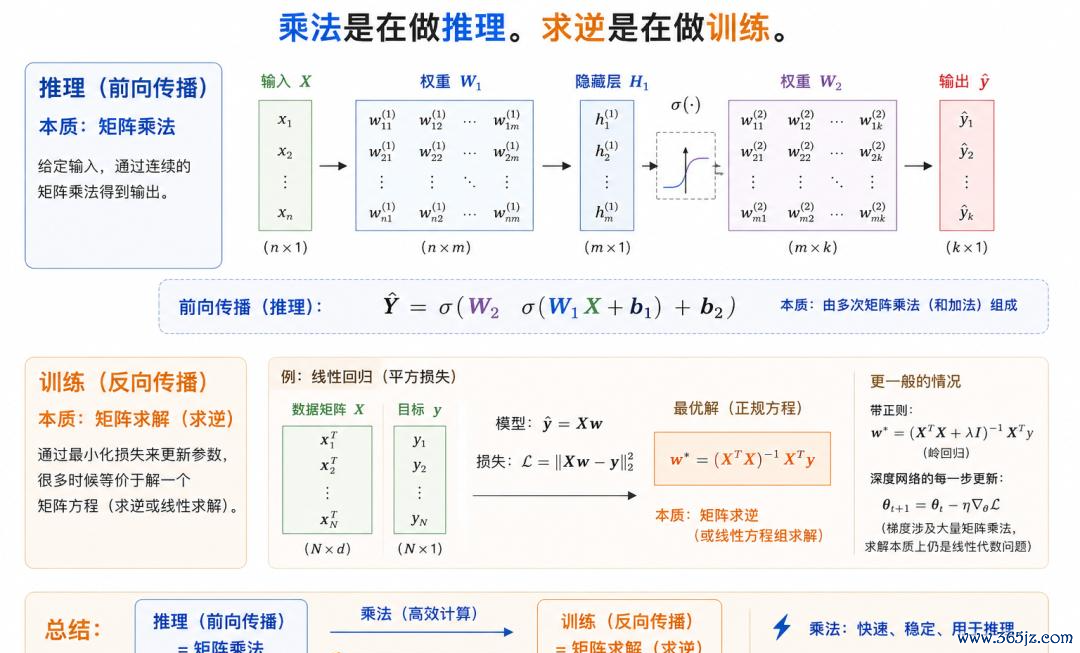
(注:今上帝流数字蓄意的作念法,依然是把底本需要径直求解的问题,转动成海量矩阵乘法,再通过不停迭代去迫临谜底。)
事实上,矩阵求逆并不局限于大模子考验。实验宇宙里信得过难的问题,许多其实都是“逆问题”。
比如,机器东谈主为什么会跌倒?自动驾驶怎么从传感器数据里还原真实景象?通讯系统怎么从夹杂信号里恢收复始信息?
这些问题,底层都在作念消释件事:从末端反推原因。
而这,恰正是GPU不擅长的。因为在数字芯片体系里,并不存在“原生矩阵求逆”这个算子。它的作念法,本色上是绕。
先把一个求逆问题斥逐,再转动成海量矩阵乘法,然后通过不停迭代,一轮轮迫临最终谜底。
是以GPU不是“径直解”,而是在“迫临解”,这亦然为什么,咱们前边会看到阿谁“一亿步”和“一步”的离别。
为了愈加深刻地意会这两者的各异,安纳还给咱们打了一个很形象的比喻。
比如你要建长城。矩阵求逆就像“砖”。而数字芯片手里其实莫得砖。它独一沙子、土壤、原料。
是以它得先和泥、烧制、成型,临了才能得到一块砖,再拿这块砖去建长城。
模拟蓄意芯片,则是径直把砖给你。你无谓再从沙子驱动。是以这不是“快少量”或者“省少量”的区别,而是蓄意范式本人不同。
一个是在不停迭代迫临。
一个则是原生求解。
安纳想作念的,即是把这块缺失了许多年的“砖”,重新补追溯。
让矩阵归模拟,让逻辑归数字
说到临了,一个很实验的问题摆在眼前:
模拟蓄意这块“砖”,到底怎么插进今天依然高度练习的AI基础措施里?
安纳给出的谜底很节略:让矩阵归模拟,让逻辑归数字。
据了解,他们的模拟芯片在接口、数据边幅和互联形式上,都兼容现存GPU体系,不错径直接入今天依然scale起来的AI Infra和算力中心。
更迫切的是,它不依赖首先进制程。
当数字芯片还在3nm、2nm上络续向物理极限迫临时,模拟蓄意某种意思意思上依然跳出了那套“拼晶体管、拼工艺、拼堆叠”的竞争逻辑。
而一朝矩阵求逆这块“砖”信得过补上,它带来的变化,可能会比设想中更大。
机器学习里的优化问题、具身智能的及时清爽已毕、自动驾驶的景象臆测、6G通讯里的信号酬报、端侧AI的在线学习……这些系统背后,本色上都在高频求解矩阵方程。
往时许多问题不是不可作念,而是太慢、太贵、太耗电。
而矩阵求逆一朝大要被原生、高精度、低功耗地完成,许多往时只可放在云表、只可离线考验、只可近似求解的事情,可能都会驱动发生变化。
是以回头再看,安纳想作念的,其实不仅仅一颗“更快更省电的芯片”。
他们信得过想切入的,是下一代智能系统最底层的蓄意形式。
2012年,东谈主们第一次意志到,GPU不仅能绘制,还能考验神经收罗。
AI期间由此开启。
而今天,安纳试图回答的是另一个问题:
要是矩阵乘法界说了往时十年的AI,那么模拟蓄意和矩阵求逆,会不会界说下一代智能系统?
至少当今欢乐炸三张金花游戏app中国官方最新版,他们依然站在了这个问题的最前排。